
NVIDIA is urging customers to enable System-level Error Correction Codes (ECC) as a defense against a variant of a RowHammer attack demonstrated against its graphics processing units (GPUs).
“Risk of successful exploitation from RowHammer attacks varies based on DRAM device, platform, design specification, and system settings,” the GPU maker said in an advisory released this week.
Dubbed GPUHammer, the attacks mark the first-ever RowHammer exploit demonstrated against NVIDIA’s GPUs (e.g., NVIDIA A6000 GPU with GDDR6 Memory), causing malicious GPU users to tamper with other users’ data by triggering bit flips in GPU memory.
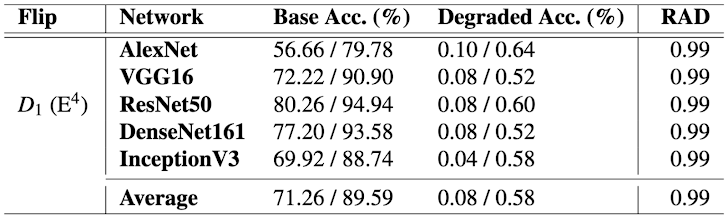
The most concerning consequence of this behavior, University of Toronto researchers found, is the degradation of an artificial intelligence (AI) model’s accuracy from 80% to less than 1%.
RowHammer is to modern DRAMs just like how Spectre and Meltdown are to contemporary CPUs. While both are hardware-level security vulnerabilities, RowHammer targets the physical behavior of DRAM memory, whereas Spectre exploits speculative execution in CPUs.
RowHammer causes bit flips in nearby memory cells due to electrical interference in DRAM stemming from repeated memory access, while Spectre and Meltdown allow attackers to obtain privileged information from memory via a side-channel attack, potentially leaking sensitive data.

In 2022, academics from the University of Michigan and Georgia Tech described a technique called SpecHammer that combines RowHammer and Spectre to launch speculative attacks. The approach essentially entails triggering a Spectre v1 attack by using Rowhammer bit-flips to insert malicious values into victim gadgets.
GPUHammer is the latest variant of RowHammer, capable of inducing bit flips in NVIDIA GPUs even with mitigations like target refresh rate (TRR) in place. Unlike CPUs, which have benefited from years of side-channel defense research, GPUs often lack parity checks and instruction-level access controls, leaving their memory integrity more exposed to low-level fault injection attacks.
In a proof-of-concept developed by the researchers, using a single-bit flip to tamper with a victim’s ImageNet deep neural network (DNN) models can degrade model accuracy from 80% to 0.1%. It’s a clear sign that GPUHammer isn’t just a memory glitch—it’s part of a broader wave of attacks targeting the core of AI infrastructure, from GPU-level faults to data poisoning and model pipeline compromise
Exploits like GPUHammer threaten the integrity of AI models, which are increasingly reliant on GPUs to perform parallel processing and carry out computationally demanding tasks, not to mention open up a new attack surface for cloud platforms.
In shared GPU environments like cloud ML platforms or VDI setups, a malicious tenant could potentially launch GPUHammer against adjacent workloads, affecting inference accuracy or corrupting cached model parameters without direct access. This creates a cross-tenant risk profile not typically accounted for in current GPU security postures.
This development ties into broader concerns around AI model reliability and adversarial ML, where attackers exploit input or memory vulnerabilities to manipulate outputs. GPUHammer represents a new class of attacks that operate below the model layer—altering internal weights instead of external data.
Its implications extend to edge AI deployments, autonomous systems, and fraud detection engines, where silent corruption may not be easily caught or reversed.
To mitigate the risk posed by GPUHammer, it’s advised to enable ECC through “nvidia-smi -e 1.” Users can verify ECC status by running nvidia-smi -q | grep ECC, which reports whether ECC is supported and currently enabled.
To minimize impact while maintaining protection, some configurations allow ECC to be selectively enabled only for training nodes or high-risk workloads. It’s also good practice to monitor GPU error logs (/var/log/syslog or dmesg) for ECC-related corrections, which can signal ongoing bit-flip attempts.
Newer NVIDIA GPUs like H100 or RTX 5090 are not affected due to them featuring on-die ECC, which helps detect and correct errors arising due to voltage fluctuations associated with smaller, denser memory chips.

“Enabling Error Correction Codes (ECC) can mitigate this risk, but ECC can introduce up to a 10% slowdown for [machine learning] inference workloads on an A6000 GPU,” Chris (Shaopeng) Lin, Joyce Qu, and Gururaj Saileshwar, the lead authors of the study, said, adding it also reduces memory capacity by 6.25%.
The disclosure comes as researchers from NTT Social Informatics Laboratories and CentraleSupelec presented CrowHammer, a type of RowHammer attack that enables a key recovery attack against the FALCON (FIPS 206) post-quantum signature scheme, which has been selected by NIST for standardization.
“Using RowHammer, we target Falcon’s RCDT [reverse cumulative distribution table] to trigger a very small number of targeted bit flips, and prove that the resulting distribution is sufficiently skewed to perform a key recovery attack,” the study said.
“We show that a single targeted bit flip suffices to fully recover the signing key, given a few hundred million signatures, with more bit flips enabling key recovery with fewer signatures.”
For industries governed by strict compliance rules—such as healthcare, finance, and autonomous systems—the silent failure of AI due to bit-flip attacks introduces regulatory risk. Incorrect inferences caused by corrupted models could violate safety, explainability, or data integrity mandates under frameworks like ISO/IEC 27001 or the EU AI Act. Organizations deploying GPU-intensive AI must include GPU memory integrity in their security and audit scopes.

{kind=link}